Introduction
Since its release in 1996, Pokemon has become an instant success spanning seven generations with more than 802 Pokemon characters. Initially released as “pocket monsters” in Japan, Pokemon became an instant hit when it first began circulating in the United States in the ’90s. The franchise largely revolved around animal-like characters in conjunction with human trainers competing in battles with each other. In the original television series, a segment of the show included attempting to guess a pokemon based on an outline of its image. The segment was called “who’s that Pokemon?”. I remember growing up watching the series and attempting to guess the Pokemon.
For this project, we wanted to do something similar to that segment of the television series. However, instead of guessing, we decided to explore building several models that could classify Pokemon based on their individual characteristics and features. Below are a few of the questions that guided the exploration.
Out of the following Statistical Methods which produces the lowest error rate when classfying the Pokemon by type?
- LDA
- Decision Tree
Using the following methods, how well do they determine whether a Pokemon is legendary or not?
- KNN
- Ridge
Lastly, how well does the singular value decomposition method differentiate between different types of Pokemon when using images?
- Singular Value Decomposition
Datasets used for the Project are listed below:
Statistical Methods and Decription of Methods
I. Type Classification Method
a. Linear Discriminant Analysis (LDA)
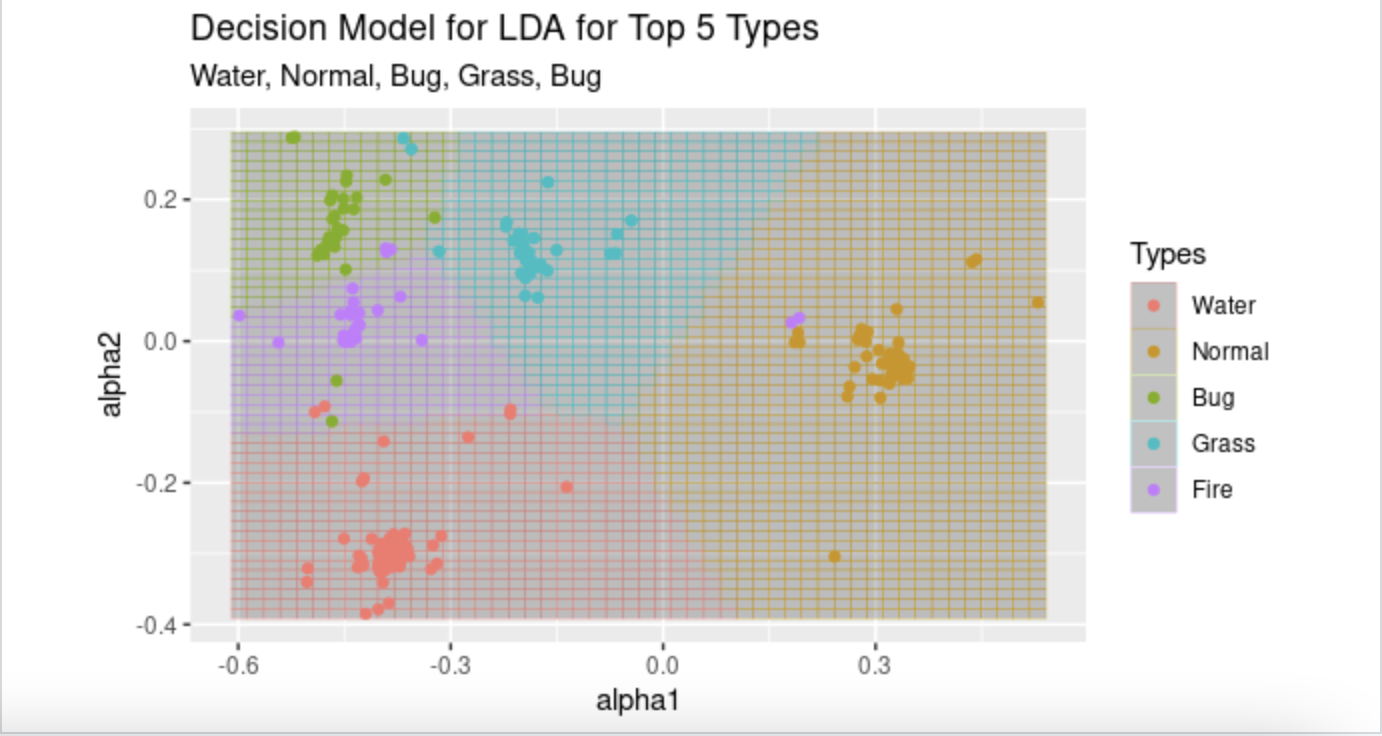
LDA is a method to find linear combinations of predictors which can separate the data into classes. The resulting coefficients can then be used to create a scaling vector which maximizes the ratio of intergroup separation and intragroup variance. This is useful for dimension reduction to then predict the model on the scaled vectors. Since there are around 30 possible predictors, this feature of LDA seemed to make sense for the project. There are 18 types of Pokemon, but the top five types (water, normal, bug, fire, and grass) make up about half of the 801 Pokemon in the dataset. We decided to run the LDA model just on these top five types to see if we could get a more simple model working on just the most common types. All of the predictors in the model were used and a scaling vector was obtained. By scaling all the coefficients for each class, we ending up with four alpha values, and then ran another LDA model on the alpha values to get our final MSE.
b. Decision Tree
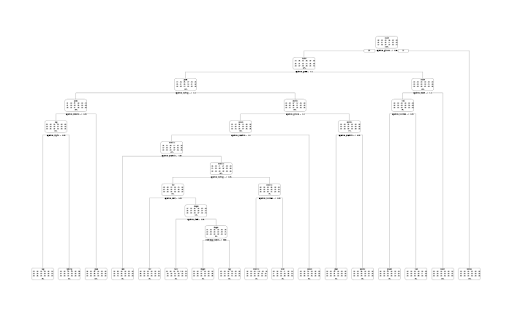
Decision Trees are a method of utilizing trees to make decisions about data. The tree is built on a sequence of decisions about the given predictors, and can be used to make qualitative predictions, or classifications. Another useful aspect of a decision tree is that essentially any type of predictor can be used to build the tree, continous, categorical, or even mixed predictors. The rpart library provides a convenient way to build trees, and also offers control over parameters that can penalize the model for building too complex of a tree, which can lead to overfitting. Since we have multiple types of predictors, and around 30 of them that we are dividing into 18 type categories, the decision tree is a good choice for our data set. After building our initial model, we found the optimal CP parameter, which penalizes overfitting, from the table the model provides, and build an optimal model using this parameter. We then can see the optimal decision tree, and the VIP plot for the model which shows us the most important predictors in making the decisions.
c. Images
For our image processing we used singular value decomposition which allowed us to run a linear model everytime we wanted to predict on a new hat,a hat refers to the eigenspace of a particular type - water, fire, etc. The process of applying singular value decomposition was challenging. Using the image data that we pulled from Kaggle, we began by converting the images into multiple csv. files for each image, but quickly found that this method was not ideal. Instead, what we had to do was create a matrix/dataset where the rows were the individual images and the columns the total number of pixels (721 * 14400). In total, we had 721 images. I created a function that read each image, converted them to greyscale and returned them as a matrix. Then, I used a for loop function to combine each image matrix into one matrix by their respective rows. Finally, to figure out the type of each Pokemon, I used our Pokemon dataset and an inner_join function to join the datasets by the pokemon name and then removed everything except for their types. We then combined them into one whole dataset with a column for their respective types. Because our dataset was so big we decided to focus only on projecting water onto fire space.
II. Legendary Classification Method
a. KNN with k-fold Cross Validation
For our first legendary classification model, we decided to use a 10-fold cross validated KNN model. KNN works by taking in a parameter k, which represents the number of closest neighbors the model takes into account. For a KNN classification, there is a vote in the neighborhood of a points k nearest neighbors, and whichever class has the most in that neighborhood is the class that point is assigned to. We also used a 10fo-ld cross validation to create our training and testing data sets for the model. Cross validation gives us more ways to reuse the data in creating more combinations of train and test sets, and allows us to tune our k parameter more finely. To do this we wrote two simple helper functions and then a used a map_dbl function to use all the folds and possible k values in order to find the optimal parameters. Since there is no penalization in the KNN model, it was seemingly overwhelmed by all the predictors and not as efficient as some of our other models.
b. Ridge Regression
Next we thought a form of penalized regression might be useful for this problem since there were so many possible predictors. Ridge regression is one type of penalized regression which seeks to minimize the mean squared error with the constraint that the sum of the squares of the coefficients are less than or equal to some parameter \( t \). The model will automatically set many unimportant predictors to zero, so the large number of predictors is narrowed down. We used cross validation to get the optimal value of \( \lambda \), which is equivalent to \( \frac{1}{t} \). Then we ran the model on a test set to get the MSE.
c. Random Forest
The third model we used to make predictions on legendary classification was a method known as random forest. Our main reason of using the random forest method, also known as bagging, is because often our optimal decision trees can be maximized and overfit our data and have a maximal depth. Thus, relatively small changes in the training set that was used for a decision tree can lead to invariably largely distinct looking decision trees. Moreover, random forest allows to use what is called “the wisdom of the crowd” wherein we can control for the error of our collection of maximal trees by averaging the errors out. Using the randomforest library from R programming. We used one-hundered trees in our random forest model, 31 random predictors choosen from our previous Pokemon dataset we created (i.e. poke.df), and used a train and test dataset to model and make predictions.
Conclusion/Results
For our type classification models, LDA had the lowest error rate, but only used five types. The decision tree was pretty effective for all 18 types. This is interesting because it shows that those that created the Pokemon and their abilities and statistics and class designation did it in a consistent way. Different types of Pokemon have a detectable pattern of statistics. There is much more we could do with this problem. For Images we would suggest, if possible perhaps using a different type of color instead of grey scale since images were largely similarly dark, and hard to distinguish, by just the greyscale color. We also think that it would be really cool to attempt this approach using images that are used on the shows’ who’s that Pokemon challenge where you have to guess the Pokemon based on an outline of what it looks like.
The legendary classification models were also all working pretty well and all had similarly small MSE, with the exception of KNN. This makes sense because legendary Pokemon are supposed to be special and more powerful, so their statistics should probably be differentiable from non-legendary Pokemon. It was also interesting to see which variables were most important. For ridge regression, we found that all of the “against” variables were most important which probably means that legendary Pokemon are more powerful against all types of Pokemon. Also, generation ended up being important when removing the “against” variables which also makes sense because there were more legendary Pokemon in later generations. The random forest model had base egg steps and capture rate as most important. Capture rate is a measure of how difficult the Pokemon is to capture, and legendary Pokemon are generally harder to capture. Overall, both of our research questions were answered with a “yes, we can build models that work pretty well.” It was really interesting to see that the Pokemon stats were created in a really specific way, and Pokemon players would be better off knowing which characteristics are prevalent in different types and what makes a legendary Pokemon different from a regular Pokemon.