Introduction
Alzheimer’s is a type of dementia that negatively impacts memory, thinking, and behavior. A dataset containing 2,159 alzheimer patients aged 60-90, along with their lifestyle and health measurements, is used to predict the diagnosis and stages of Alzheimer’s disease. For predicting diagnosis, a Random Forest, Logistic Regression, and Gradient Descent/Boosting are used on a subset of features, with a Decision Tree using only impairment assessment scores. K-means Clustering is used to group the three stages of Alzheimer’s. Results show the decision tree yields the highest accuracy of $\approx 91\%$, followed by Gradient Boosting of $\approx 85\%$ accuracy, while clustering did not show a large separation among clusters, suggesting large overlaps among patients in each cluster.
Variables
| Lifestyle | Description |
|---|---|
| Body Mass Index | 15–40 |
| Smoking Status | 0 = No, 1 = Yes |
| Alcohol Consumption | Weekly alcohol consumption in units, ranging from 0 to 20 |
| Physical Activity | Weekly physical activity in hours, ranging from 0 to 10 |
| Medical History | Description |
|---|---|
| FamilyHistoryAlzheimers | Family history of Alzheimer’s Disease, 0 = No, 1 = Yes |
| CardiovascularDisease | Presence of cardiovascular disease, 0 = No, 1 = Yes |
| Diabetes | Presence of diabetes, 0 = No, 1 = Yes |
| Depression | Presence of depression, 0 = No, 1 = Yes |
| HeadInjury | History of head injury, 0 = No, 1 = Yes |
| Hypertension | Presence of hypertension, 0 = No, 1 = Yes |
| Impairment Assessments | Description |
|---|---|
| MMSE | Mini-Mental State Examination score, ranging from 0 to 30 |
| FunctionalAssessment | Functional assessment score, ranging from 0 to 10 |
| MemoryComplaints | Presence of memory complaints, 0 = No, 1 = Yes |
| BehavioralProblems | Presence of behavioral problems, 0 = No, 1 = Yes |
| ADL | Activities of Daily Living score, ranging from 0 to 10 |
Random Forest model
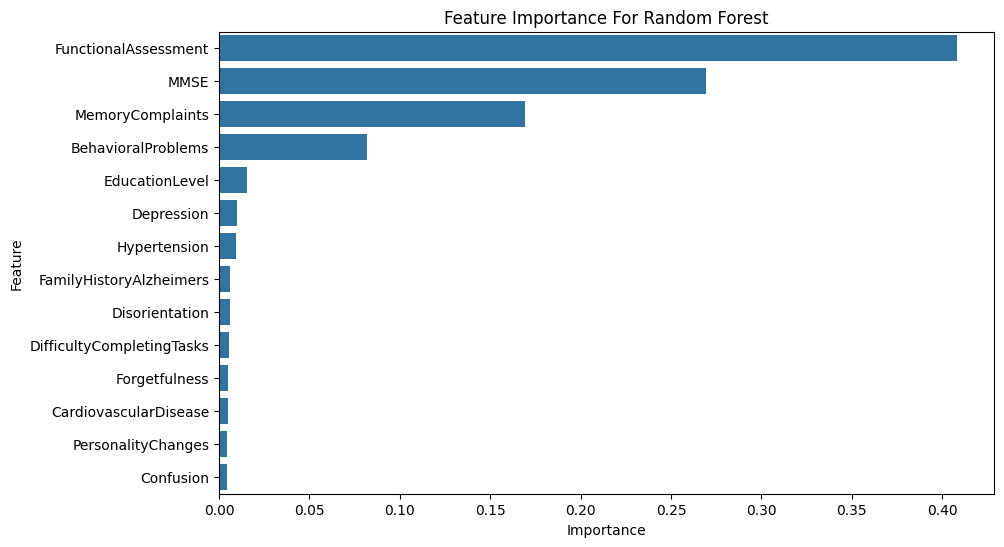
The Random Forest Classifier works by bootstrapping training data to create N subsets, training N decision trees with random feature subsets. Max depths of 4 and 8 decision trees for the strongest performance are used in our model. Oversampling is used to address the underrepresentation of positive diagnoses. The relevant variables used in the analysis are shown in the figure below.
Logistic Regression Model
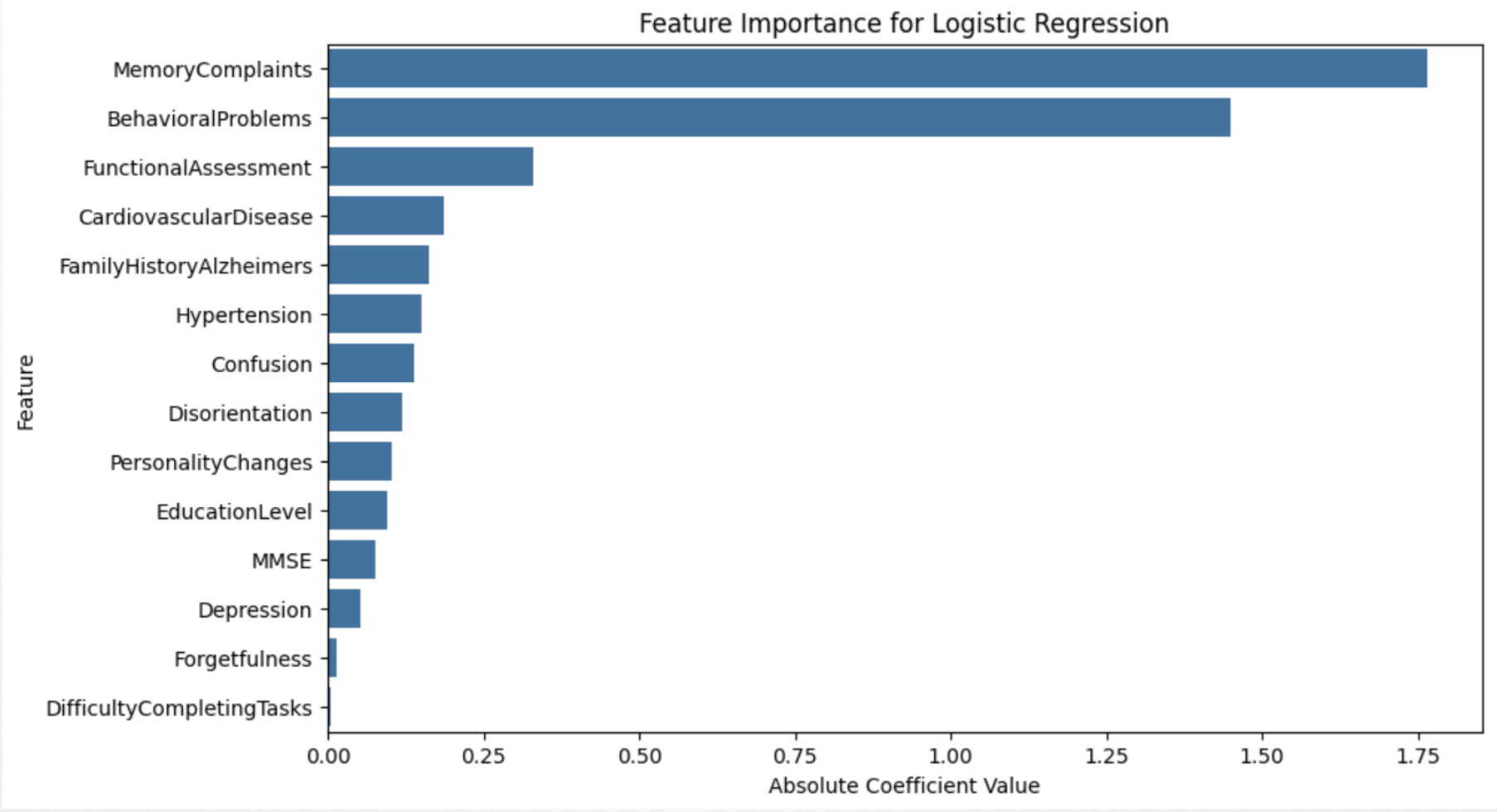
Logistic regression is employed to predict Alzheimer’s diagnosis, providing greater interpretability by offering clear insights into the impact of each predictor variable on the outcome. Logistic regression doesn’t capture complex non-linear relationships within the data. The same features as Random Forest are utilized to predict the target variable, Diagnosis. The model is optimized using a grid search for hyperparameters, specifically tuning the regularization parameter C, which controls the trade-off between fitting the training data well and avoiding overfitting.

Gradient Descent/Boosting
Gradient Boosting minimizes prediction error by using existing models and optimized datasets. It enhances prediction accuracy, ROC curves, and Alzheimer’s diagnosis accuracy by minimizing false negatives and false positives. Though extremely effective, it can suffer from over-fitting. The same variables as Random Forest and Logistic Regression are used but focus on minimizing MSE and cross-entropy. Prediction results and AUC are shown in the figure below.

Decision Trees
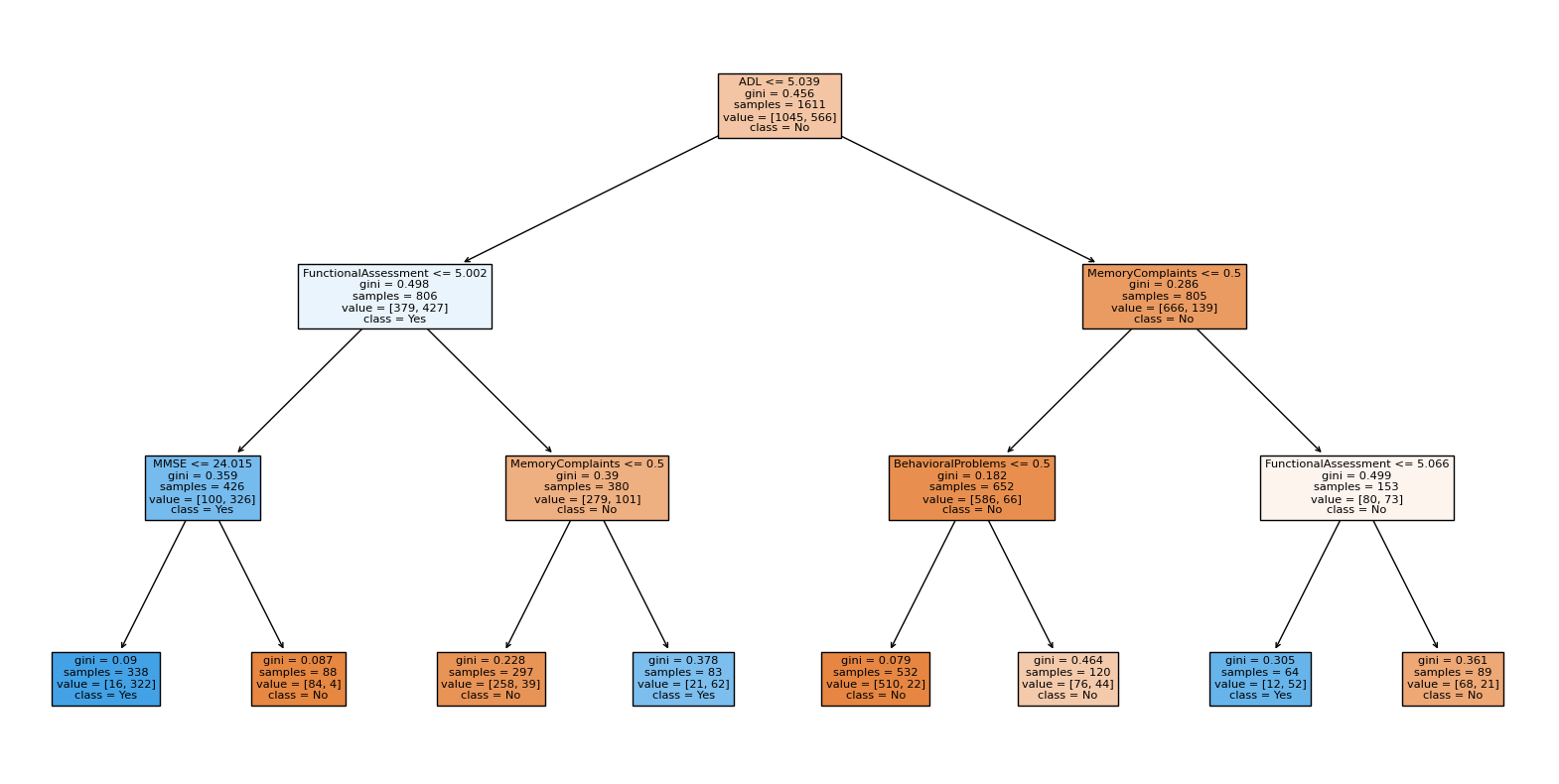
Decision Trees are easy to interpret and can concisely classify stages of cognitive impairment. This classifier uses MMSE, Functional Assessment, Memory Complaints, Behavioral Problems, and ADL against the target variable, Diagnosis. A max depth of 3 is used.
K-means Clustering
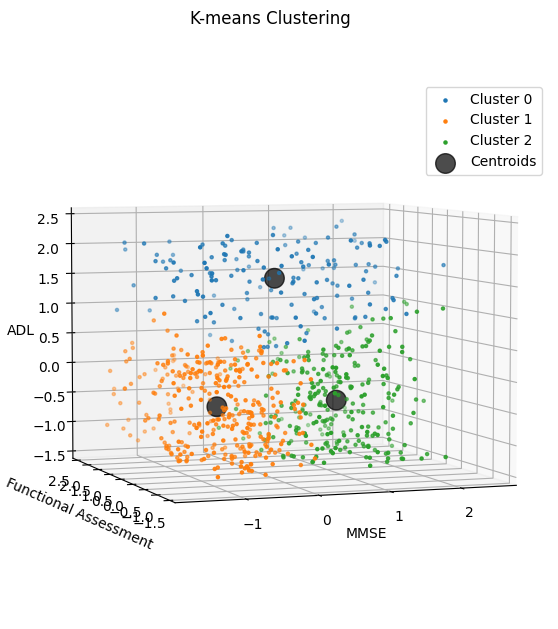
K-means Clustering is used to identify the mild, moderate, and severe stages of Alzheimer’s using MMSE, ADL, and Functional Assessment scores for patients with a positive diagnosis and unlabeled stages. Assessment scores are standardized for comparability. Using K=3, a max iteration of 100, and a random initial centroid.
Results
Our analysis results demonstrate that Gradient Boosting yields the highest TPR, while Logistic Regression yields the lowest. The Decision Tree using cognitive and functional assessment scores reached $\approx 91\%$ accuracy. In identifying the three stages of Alzheimer’s, the iterations converged to form three clusters, separated by average ADL and MMSE values. Notably, cluster 0 included patients with above-average ADL, suggesting greater independence and mild severity. In contrast, the other two clusters with both below-average ADL and at least one below-average test score indicate greater impairment.
Conclusion
Predicting Alzheimer’s diagnosis using demographic details, lifestyle factors, and medical history is feasible, with Random Forest achieving $\approx 83\%$ accuracy and Logistic Regression $\approx 77\%$. Gradient Descent/Boosting further improved model performance, resulting in $\approx 85\%$ accuracy alongside $\approx 93\%$ score, indicating a stronger differentiation between positive and negative cases. Classifying patients into different stages of cognitive impairment using cognitive and functional assessment scores proved effective, with a Decision Tree model achieving $\approx 91\%$ accuracy. Future work could integrate additional data sources such as genetics and deep learning techniques to enhance diagnostic accuracy and classification of Alzheimer’s severity.
References
Alzheimer’s and Dementia. Alzheimer’s Association, 2024. Available: alz.org.
El Kharoua, R. Alzheimer’s Disease Dataset. Kaggle, 2024. Available: alzheimers dataset.